Deep Learning pour l’amélioration de signaux vocaux captés avec des transducteurs intra-auriculaires
CFA 2022 - Marseille : Acoustique de la Parole
Machine Learning et traitement du signal avancé
appliqués à l’acoustique, la musique, et la parole
Julien HAURET, Éric BAVU, Thomas JOUBAUD, Véronique ZIMPFER
Laboratoire de Mécanique des Structures et des Systèmes Couplés,
Cnam, Paris
11/04/2022

Contexte
Contexte
Problématique


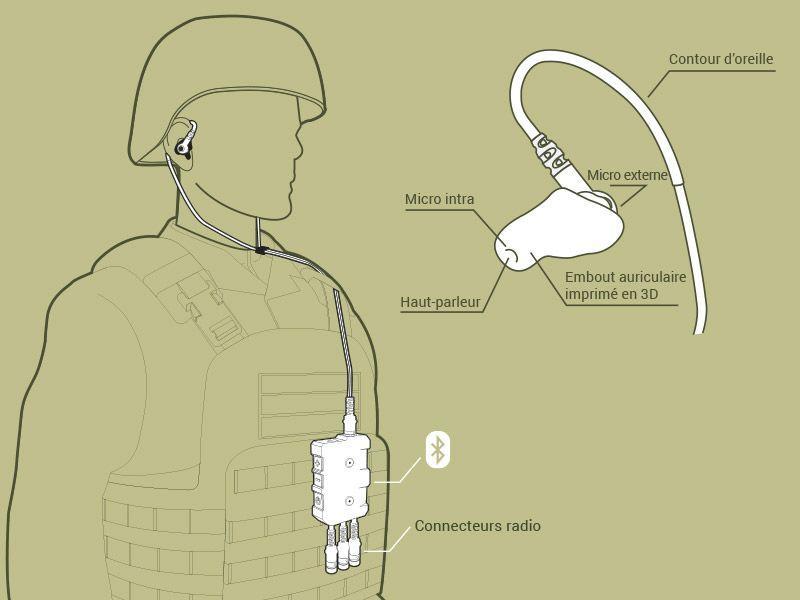
Capter la parole dans un environnement bruité
Solution
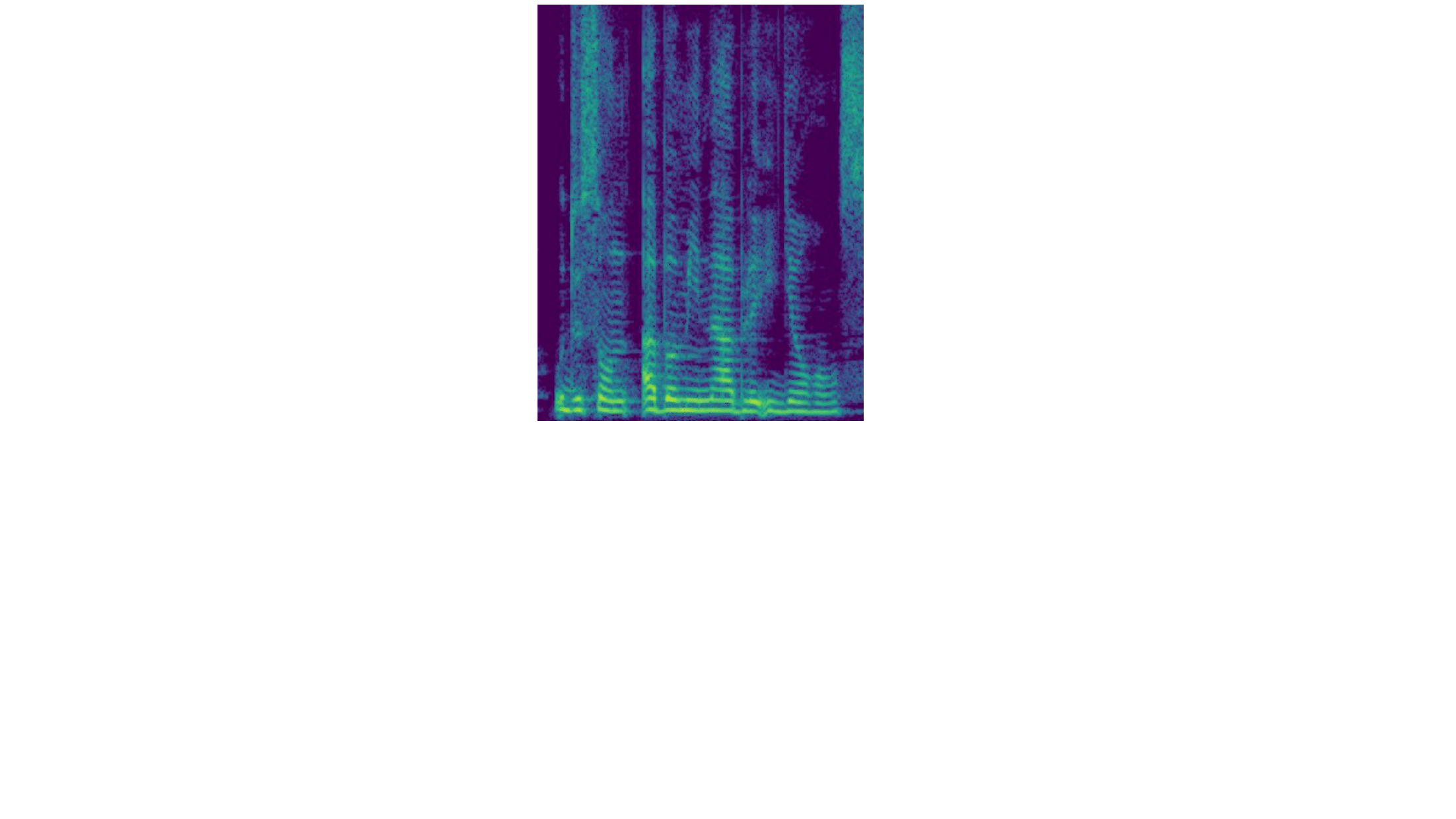
Représentation temporelle
Représentation fréquentielle
Signal de référence : x
Signal intra-auriculaire : y
Atténuation fréquentielle
Résumé
Objectif
Améliorer l'intelligibilité de la parole captée avec les transducteurs intra-auriculaire
Contraintes
- Dispositif matériel léger
- Traitement en temps réel
- Robustesse
Première approche naïve
Reconstruction avec le modèle source-filtre
\[\tilde{x}(t)=IFFT~[~ \frac{Y(f)}{H(f)} ~] \]
Signal reconstruit
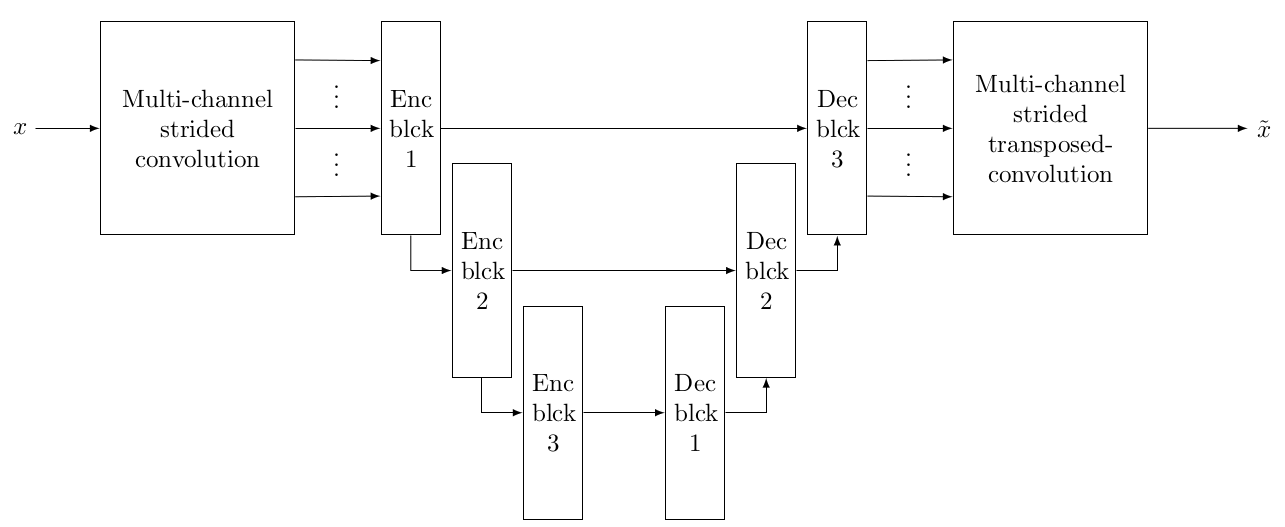
Approche par apprentissage profond
Méthode reconstructive : principe
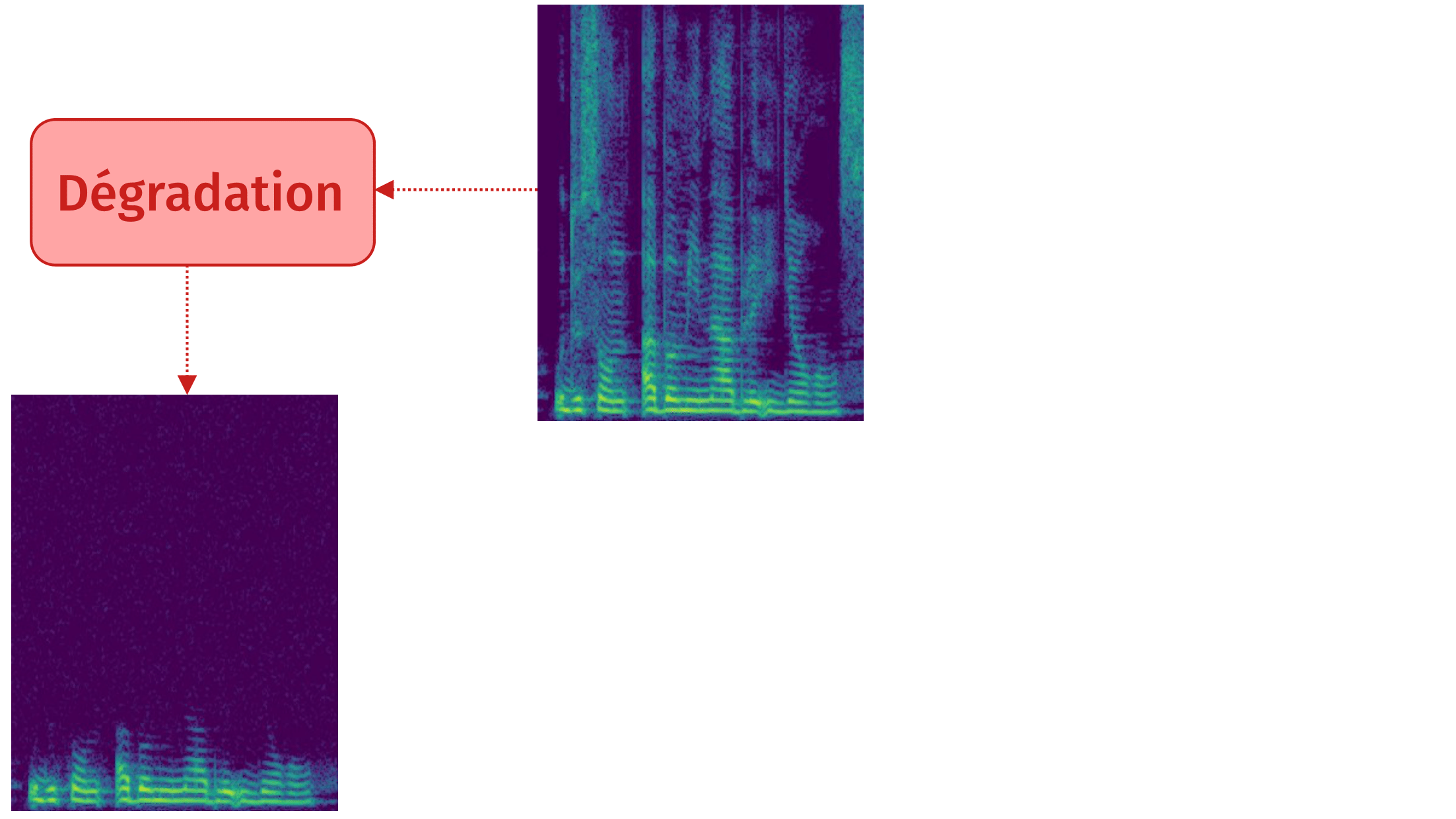
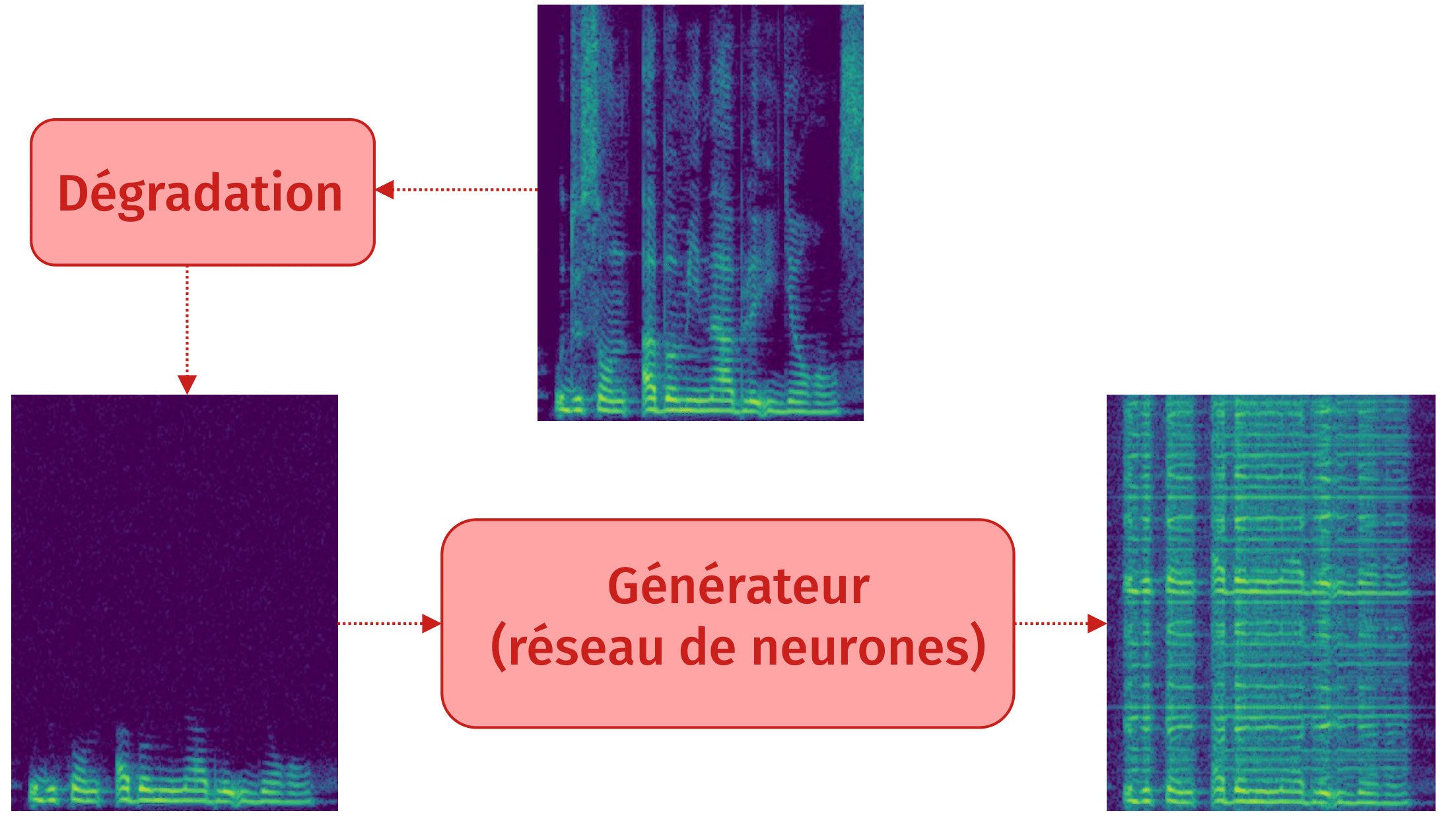
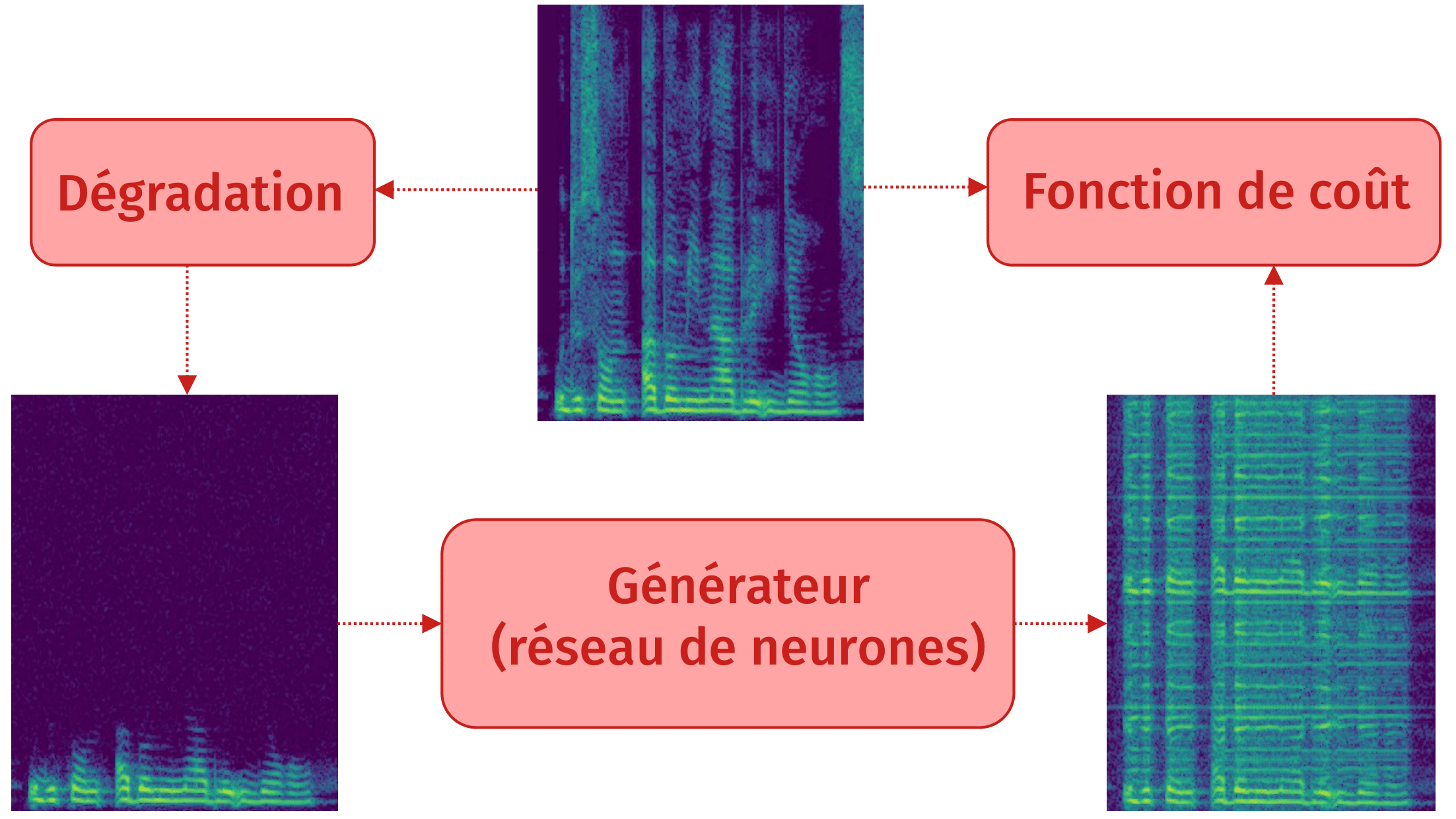
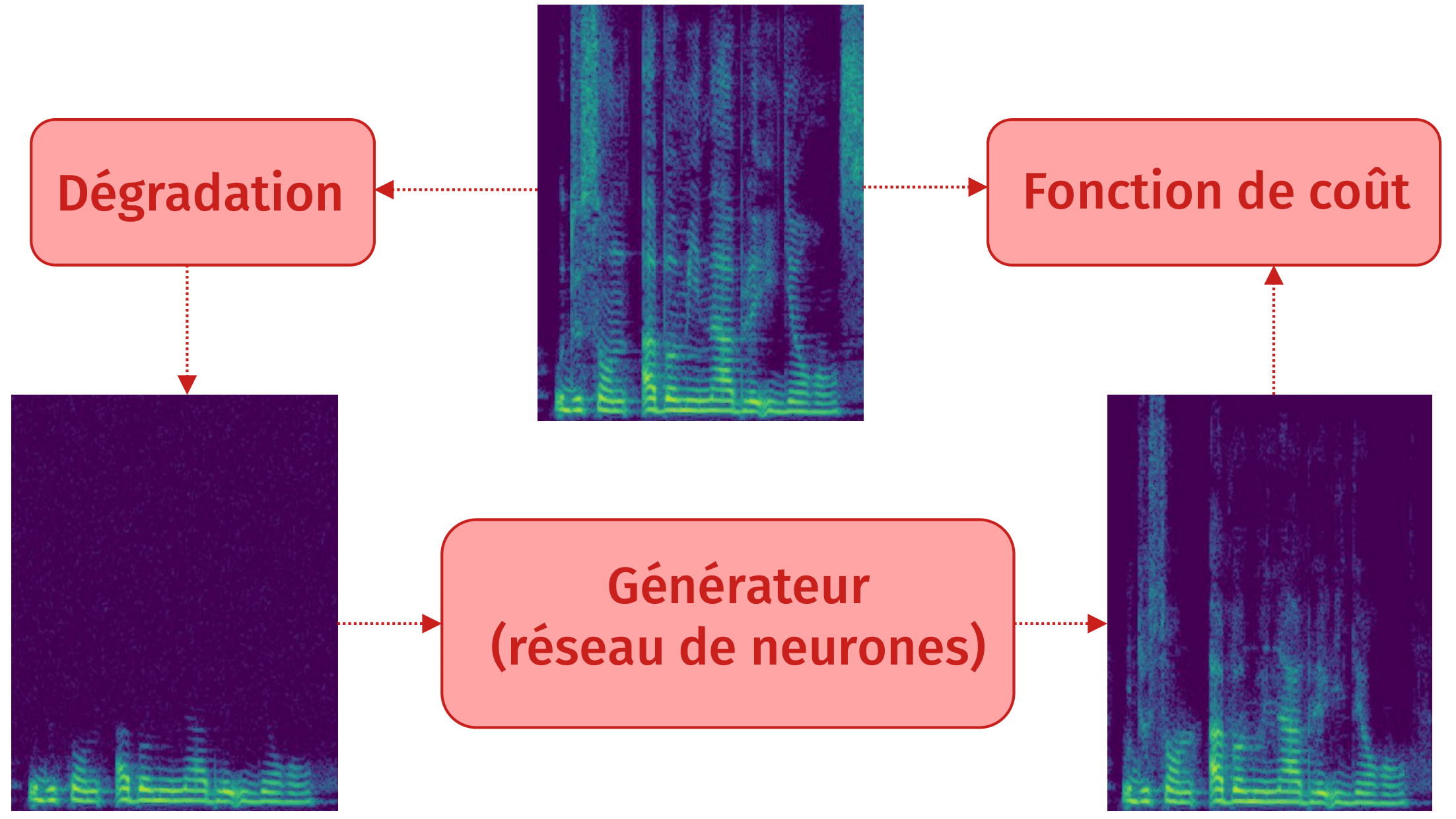
Méthode reconstructive: résultat
Méthode mixte : principe
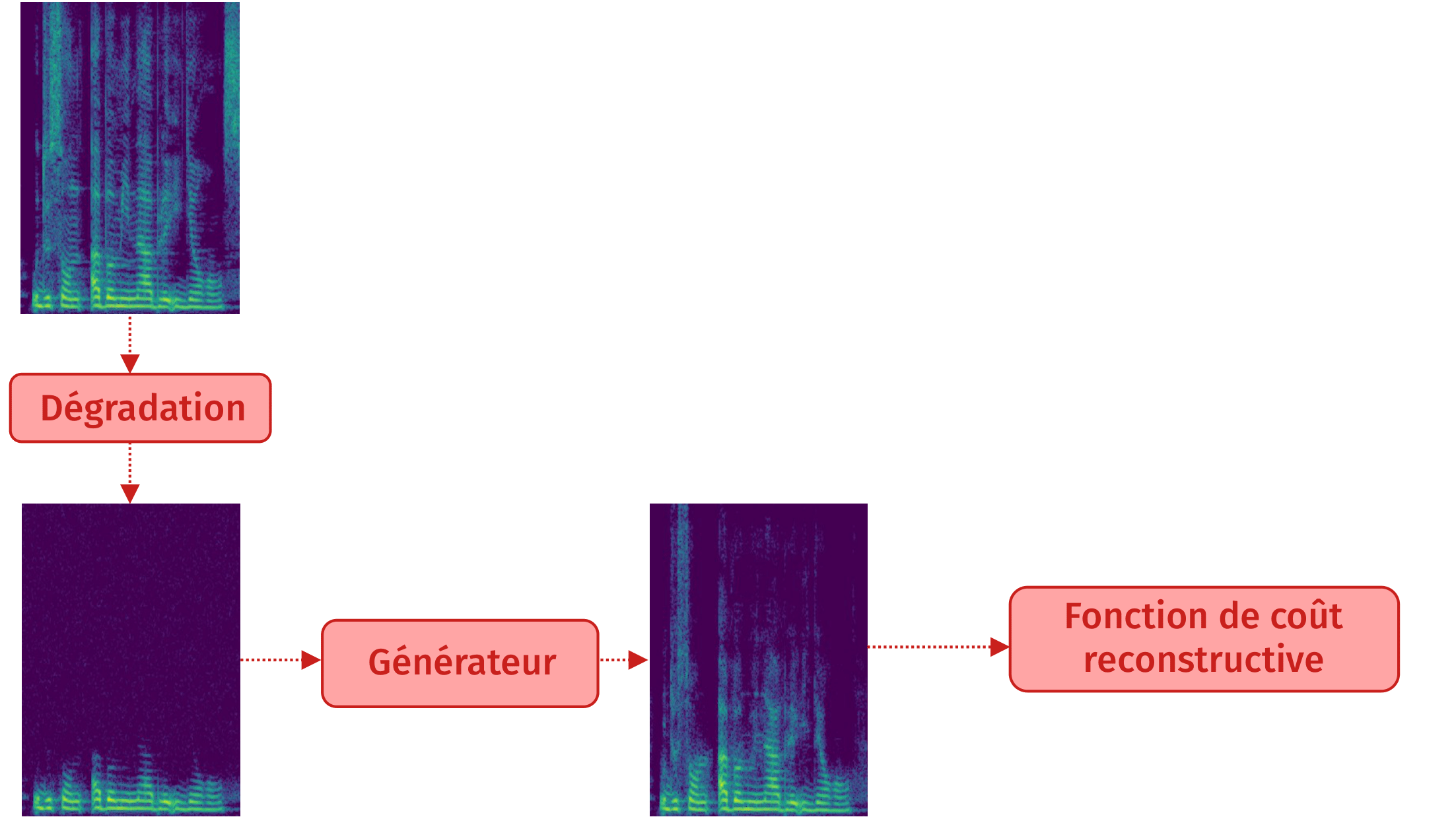
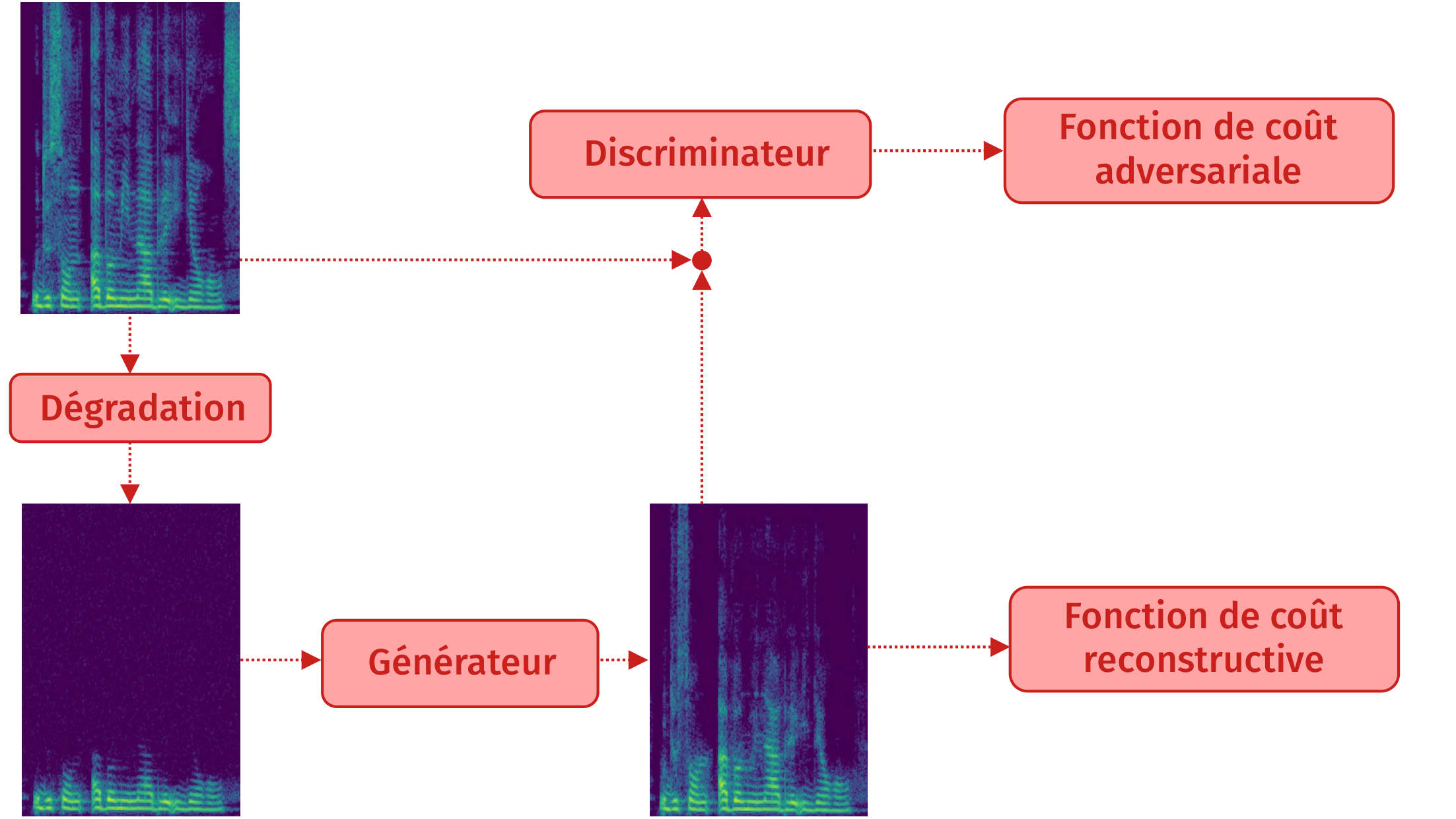
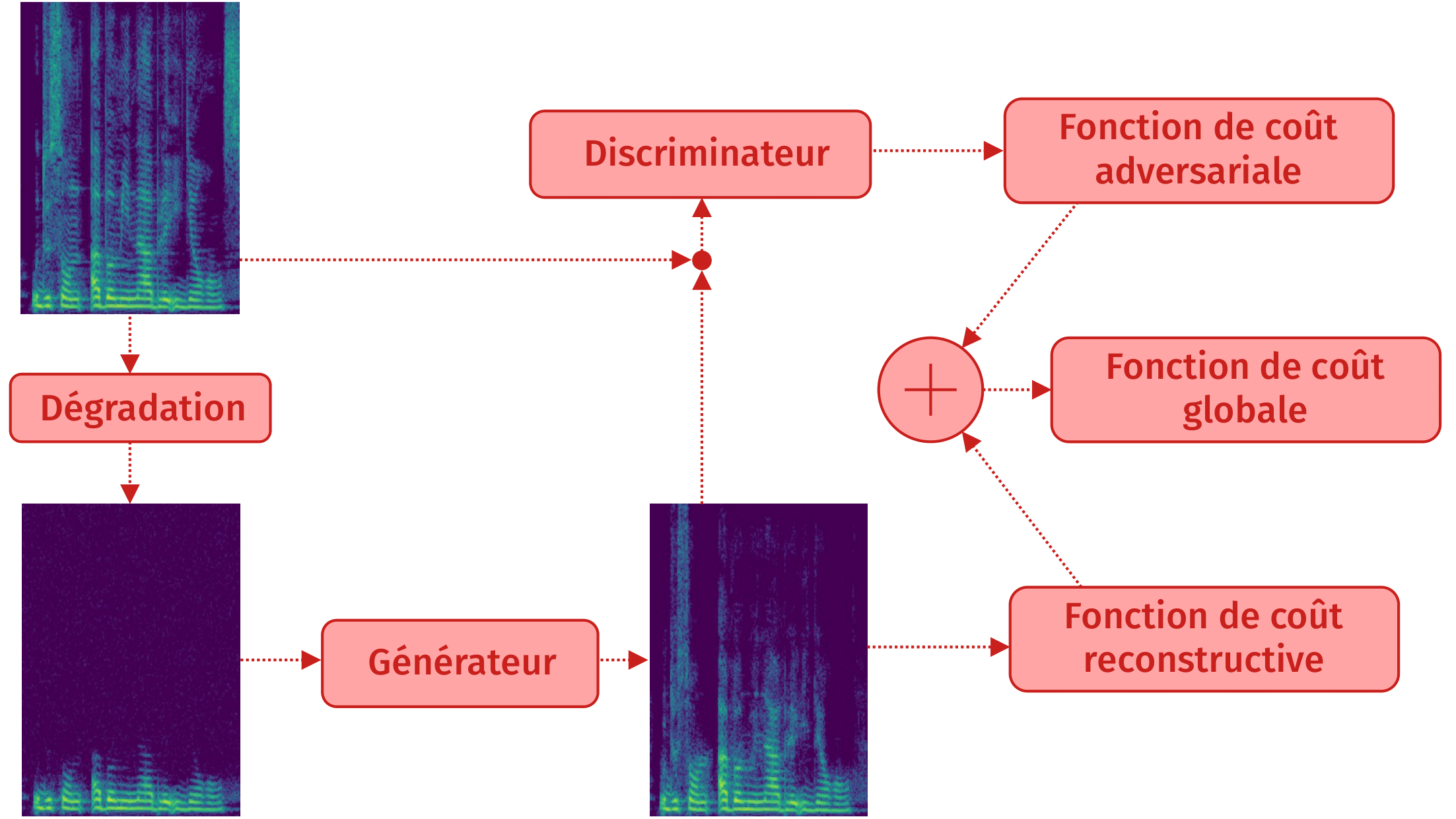
Méthode mixte : résultat
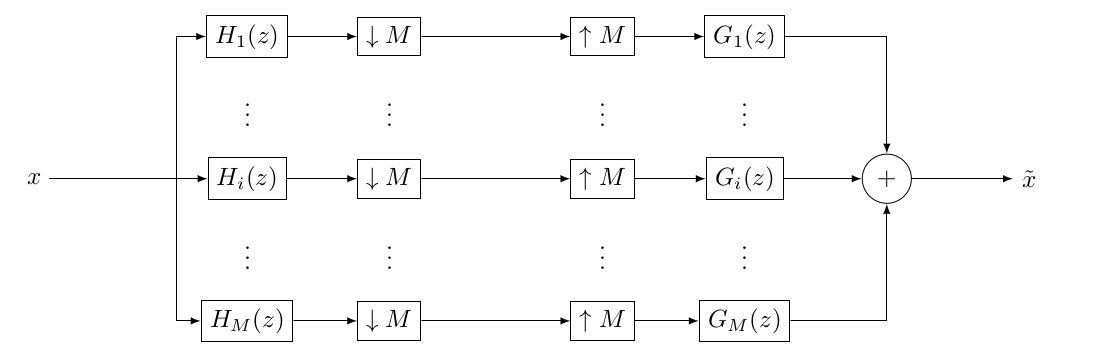
Approche par PQMF/réseau de neurones
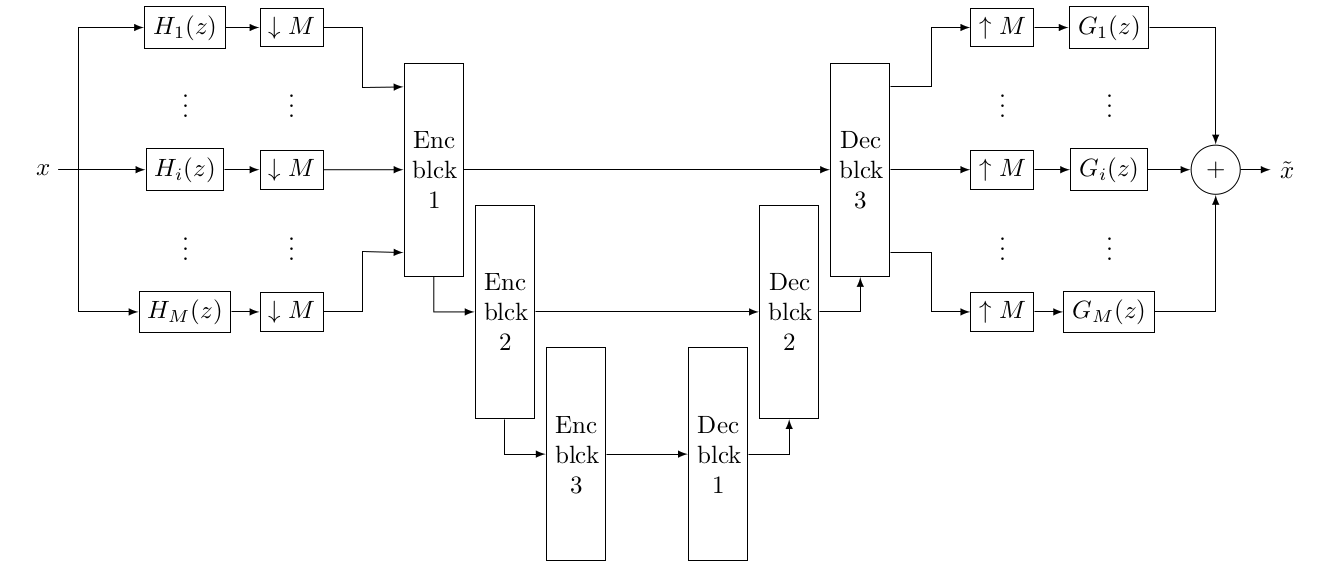
Évaluation des approches
Évaluation des approches
| Signaux | PESQ | SI-SDR | SI-SNR | STOI |
|---|---|---|---|---|
| Intra-auriculaire | 1.246 | -6.615 | -7.538 | 0.7178 |
| Mixte | 2.321 | 10.99 | 10.79 | 0.8985 |
| Mixte - PQMF | 2.573 | 11.25 | 11.05 | 0.8961 |
Conclusion
Points clés des transducteurs intra-auriculaire
- Large contexte applicatif
- Information haute fréquence à retrouver recréer
- Piste suivie: PQMF + Apprentissage profond
Merci de votre attention
julien.hauret@lecnam.net
Laboratoire de Mécanique des Structures et des Systèmes Couplés,
Cnam, Paris
Annexes
Signal processing equations
Source-Filter model
\[y(t) = (h*x)(t) \]
\[Y(f) = H(f).X(f) \]
Transfer function estimation
\[H(f)=\frac{P_{xy}(f)}{P_{xx}(f)} \]
\[C_{xy}(f)=\frac{|P_{xy}(f)|^2}{P_{xx}(f) . P_{yy}(f)} \]
Bode diagram
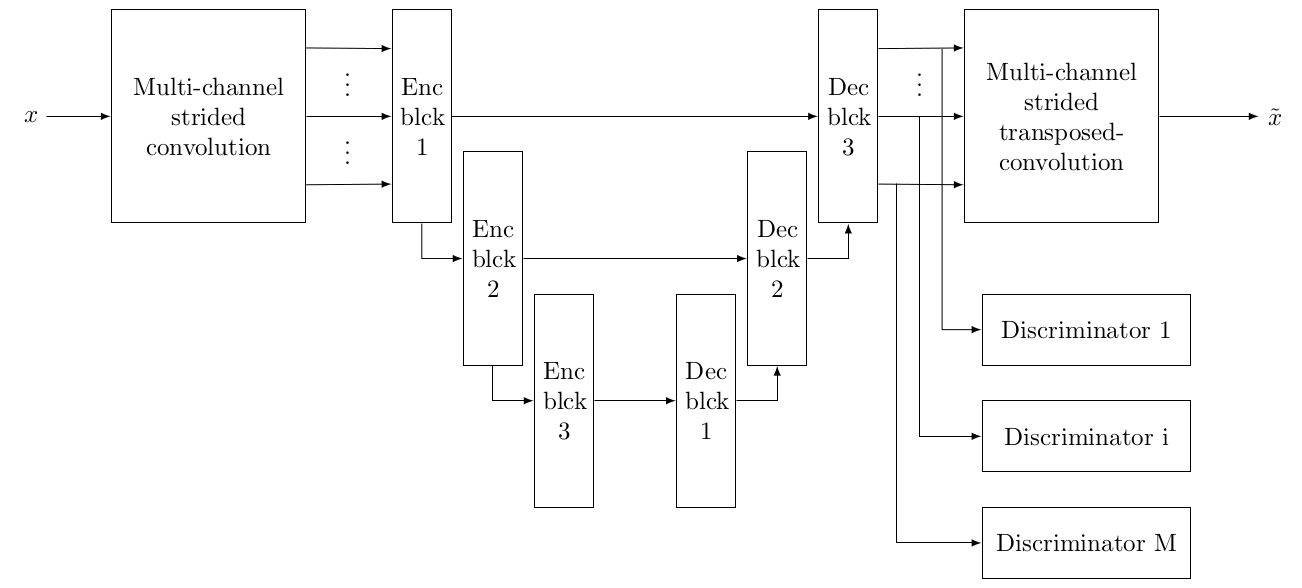
Fonction de coût : SeaNET
\[\mathcal{L_D}= E_y\left[ \frac{1}{K} \sum_k \frac{1}{T_k} \sum_t max(0,1-D_{k,t}(y))\right] + E_x\left[ \frac{1}{K} \sum_k \frac{1}{T_k} \sum_t max(0,1+D_{k,t}(G(x)))\right]\] \[\mathcal{L_G^{adv}}= E_x\left[ \frac{1}{K} \sum_k \frac{1}{T_k} \sum_t max(0,1-D_{k,t}(G(x)))\right]\] \[\mathcal{L_G^{rec}}= E_x\left[ \frac{1}{KL} \sum_{k,l} \frac{1}{T_{k,l}} \sum_t \| D_{k,t}^{(l)}(y)-D_{k,t}^{(l)}(G(x))\| _{L_1} \right]\]Références - 1
PQMF
- Joseph Rothweiler: Polyphase quadrature filters–a new subband coding technique. In ICASSP 1983.
- Truong Q Nguyen: Near-perfect-reconstruction pseudo-qmf banks. In 1994 IEEE.
- Yuan-Pei Lin & al: A kaiser window approach for the design of prototype filters of cosine modulated filterbanks. In 1998 IEEE.
Deep learning
- Marco Tagliasacchi & al: Seanet : A multi-modal speech enhancement network. arXiv preprint, 2020.
Références - 2
Métriques
- Antony W Rix & al : Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In 2001 IEEE.
- Cees H Taal & al: A short-time objective intelligibility measure for time-frequency weighted noisy speech. In 2010 IEEE.
- Jonathan Le Roux & al: Sdr–half-baked or well done ? In ICASSP 2019.
- Yi Luo & al : time-domain audio separation network for real-time, single-channel speech separation. In 2018 IEEE.